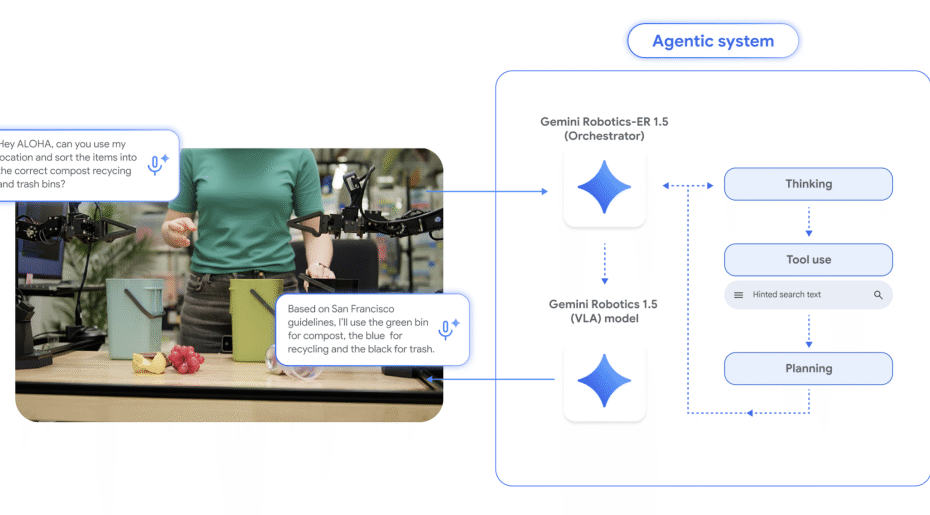
Checklists Are Better Than Reward Models For Aligning Language Models Apple Machine Learning Research
Language models must be adapted to understand and follow user instructions. Reinforcement learning is widely used to facilitate this — typically using fixed criteria such as “helpfulness” and “harmfulness”. In our work, we instead propose using flexible, instruction-specific criteria as a means of broadening the… Read More »Checklists Are Better Than Reward Models For Aligning Language Models Apple Machine Learning Research